2025 Girls Astronomy Summer Camp Report
T. Andrew Manning, Research Scientist, National Center for Supercomputing Applications
Summary
I supported another successful UIUC Girls Astronomy Summer Camp, which was held July 7-11, 2025. This year I again deployed a dedicated JupyterHub service that allowed the students to run code in Jupyter notebooks independently on their own JupyterLab servers during the three tutorial sessions. My points of contact was camp instructor Janiris Rodriguez-Bueno.
Identity and access management
Because they are in high school, the students needed local accounts that do not rely on an email address or a third-party service. Following last year’s method, I used the NativeAuthenticator plugin that makes it easy for hub admins to dynamically authorize users as they sign up to create their local JupyterHub accounts during the first tutorial session. This solution is the simplest while providing the most flexibility and control to the GASC instructors. Students can create their own username and password, and all the hub admins need to do is click the authorize button. Forgotten passwords can be easily reset by hub admins as needed.
Resource allocation and limits
This year we had 10 worker nodes (16 CPU / 60 GB each) at our disposal from an existing Kubernetes cluster that hosts the MUSES Calculation Engine service and the SPT-3G cutout service. To lower the risk of crashing nodes, I cordoned three of the workers to run the GASC JupyterLab servers and scaled back the other project services to confine them on the remaining nodes.
Each worker node had roughly 100GB available for fast local storage volumes, used to provide 1GB private storage to each server. A higher capacity NFS-mounted storage volume was mounted at /home/jovyan/shared, providing a shared filesystem between all servers.
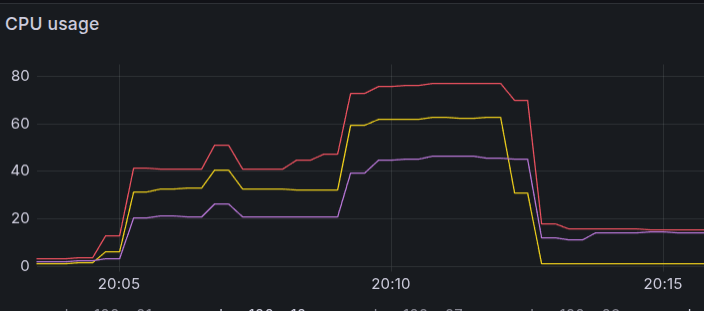
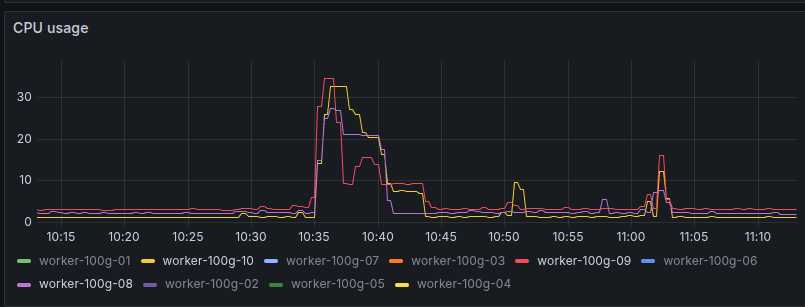
There were 15 servers running concurrently during the tutorial sessions. The first two sessions consumed so little CPU it was not visible above the baseline “noise” in the usage chart. The third session, however, involved running machine learning algorithms to analyze data. A full run of the “solved” notebook took about 8 minutes in testing, during which the host server railed its limit of 2 cpu. During the tutorial session, the resource usage was significant, peaking around 6 cpu per worker node. The resource limits worked effectively to prevent destabilizing the worker nodes.
Testing
To test that the system could handle the maximum resource use while running all machine learning notebooks concurrently, I wrote a script to upload the solved notebook to all the servers and executed them via command line (jupyter execute /path/to/notebook.ipynb). The servers were launched using the button on the /hub/admin page.
#!/bin/bash
pods=(
jupyter-vera-rubin---1197276e
jupyter-ayn-rand---e13bf457
...
)
for pod in "${pods[@]}"; do
echo $pod
kubectl cp -n gasc-jupyterhub /home/andrew/Downloads/SeparatingStarsAndGalaxies_solved.ipynb ${pod}:/tmp/
done
for pod in "${pods[@]}"; do
echo $pod
kubectl exec -it -n gasc-jupyterhub ${pod} -- jupyter execute /tmp/SeparatingStarsAndGalaxies_solved.ipynb &
done